
社内ミニクラウドと2つのLLM
今回は2つの日本語LLMを使って何ができるか、を試してみます。

以下2つの日本語LLMを使わせて頂きました。
生成型 :Elyza (文章を読んで要約したり、文章を生成したりします)
数値型 :cl-tohoku (文章を読んで、意味ベースで数値化します)
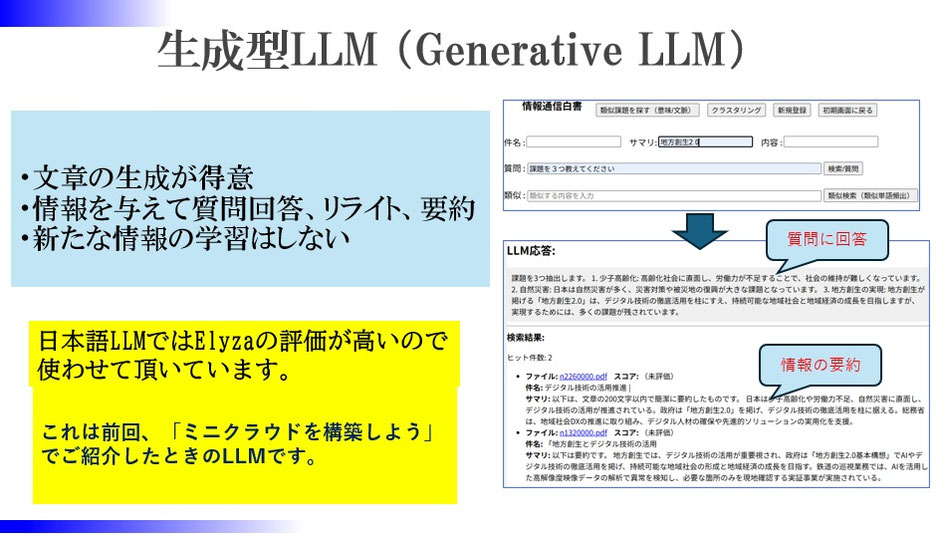
生成型のLLMは前回の「ミニクラウドを構築しよう」で紹介させて頂きました。

文章を渡すと768次元の数値に置き換えられます。これをどう使うのでしょう?
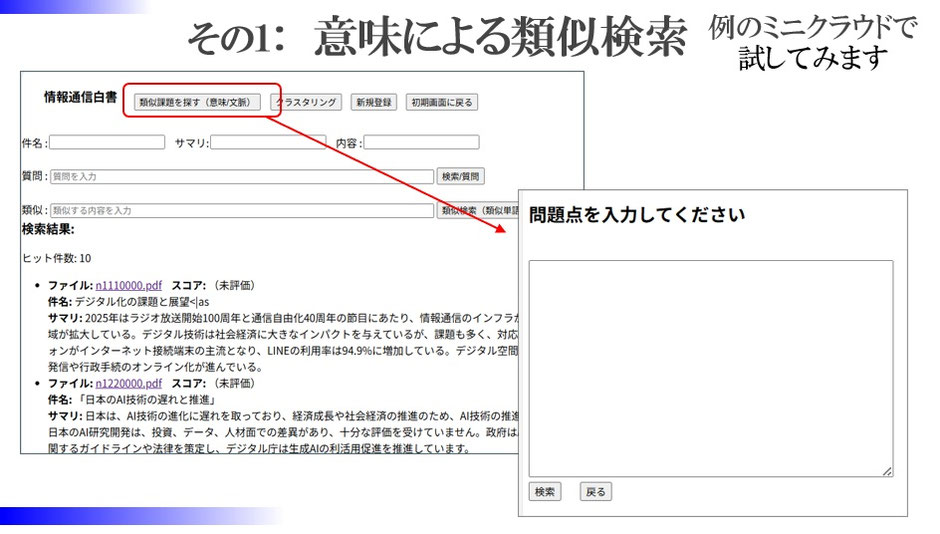
数値型LLMは意味ベースにで文章を捉えるのが特徴です。
そこで最初に、類似検索をしてみます。

文章を書いて検索すると、意味が類似するファイルが検索されます。
またスコアで類似度の高いものから順に並びます。

文章に対する類似検索は、種類があります。
数値型LLMは文章の意味を数値に置き換え、数値の比較で類似度を測定することができます。
同じ単語の頻出度で測定する方法に比べて、意味や文脈で内容の近さを測れるのです。
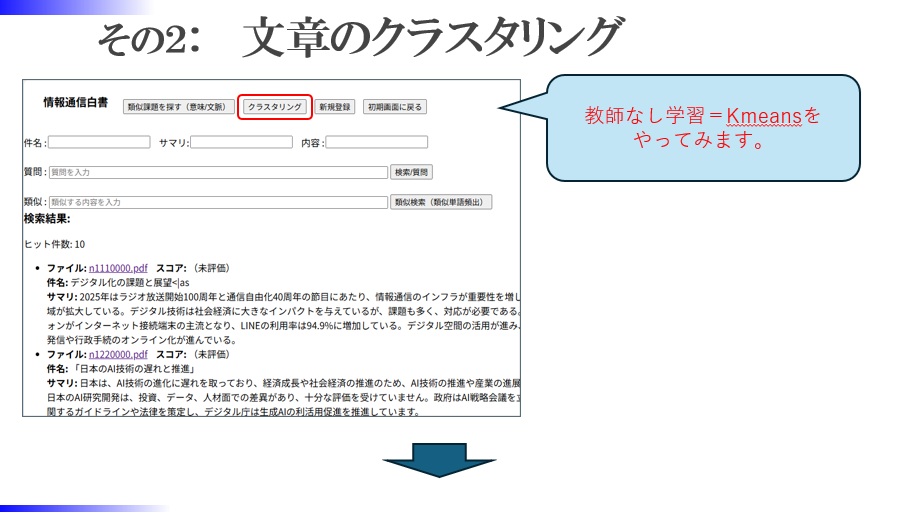
教師なし学習=Kmeansをやってみます。
文章を内容に沿って分類分けします。

Kmeansではクラスタ数を指定せず、何種類に分けるのが丁度よいかを測定して分けています。
また生成型LLMで、それぞれの内容を読んでテーマを出力することで、それぞれのクラスタに意味付けをします。
情報全体を俯瞰視することができます。

教師アリ学習もやってみましょう。
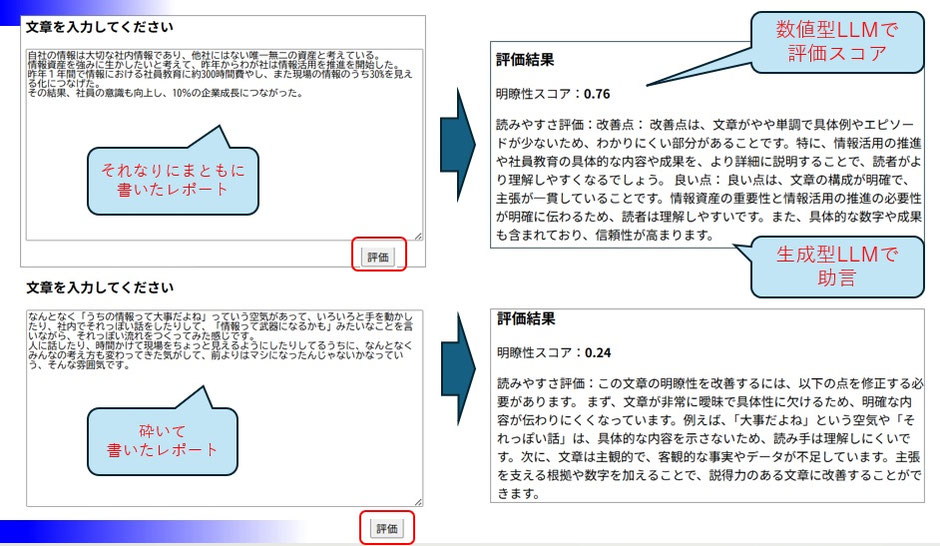
新しいレポートの書きぶりを見て、評価します。
内容がわかりやすいかどうかを数値判定してスコア表示=数値型LLM、
その数値に沿ってプロンプトを使い分けてアドバイスを表示=生成型LLM、
いかがでしょう。
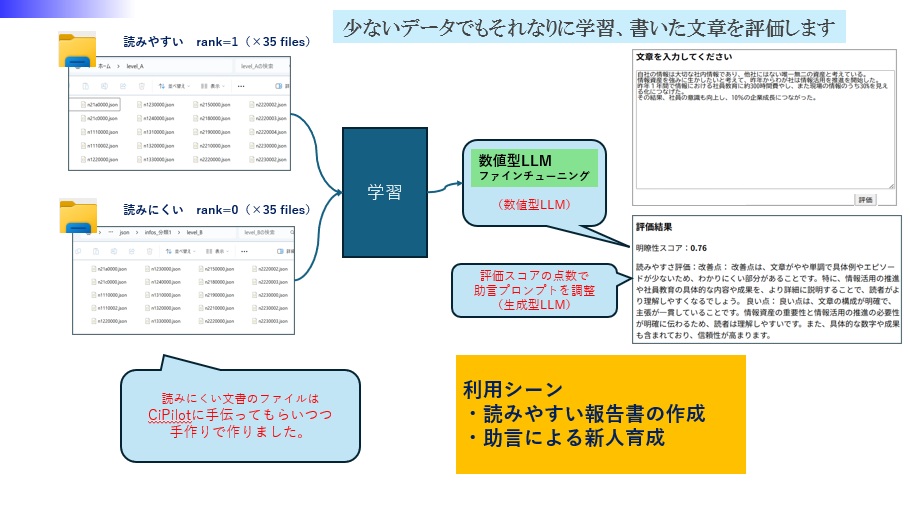
少ないファイル数でも、それなりに学習してくれました。
さて、今回は生成型LLMと数値型LLM、2種類のオープンソース。
いずれも日本のオープンソースのIT技術者の方々に、敬意と感謝を持って使わせてもらいました。
オープンソースは、それぞれが異なる設計思想を持って作り上げているので、それぞれ補い合える使い方を生み出すことができれば、不思議なコラボが生まれます。
あとは使う側のアイデア次第。
構想、創造、発想があればいくらでも可能性が広がります。
オープンソースの技術をもっと使って、可能性を一緒に広げていければ、
日本のスタートアップ企業にも、もっと機会が提供されると信じています。
櫻井 敏明